 2632 Views
2632 Views April 9, 2025
April 9, 2025
Did it ever cross your mind how a virtual assistant somehow knows exactly what you need or how search engines predict what you are typing? Well, all that is possible due to Natural Language Processing (NLP). Natural language processing is an emerging field of artificial intelligence that studies how people and computers interact.
The common task of machines in Natural Language Processing (NLP) is to comprehend human speaking analysis and writing. This technology allows machines to carry out tasks like data sorting, sentiment analysis, Text analysis, abstracting, producing, translating, and so forth.
In this blog, we will discuss the basic concepts and principles of NLP, discuss its elements, and explain how it is used. So, Let’s get started!
What is Natural Language Processing (NLP)?
Natural language Processing, shortly known as NLP is an interesting subfield of Artificial Intelligence that deals with the improvement of natural conversation between humans and the computer. In layman’s terms, it is about how to get a machine to learn a language to a level where it can intelligently interact with us.
NLP integrates machine learning techniques, deep learning algorithms, neural networks, and computational linguistics to process large volumes of natural language input. The main goal? To reduce the current gap between the natural language and the language that computers and Artificial Intelligence can comprehend.
It includes many processes, including opinion mining, translation, and speech recognition. In other words, NLP is an attempt to ensure that communication with machines is as natural and productive as possible!
If you desire to enhance your business processes, the appropriate decision is to select the best natural language processing services. These services can help you communicate, complete many different actions, and even gain insights from your data. Typically, natural language processing is separated into two distinct domains.
Natural Language Understanding (NLU)
Natural Language Understanding (NLU) is the study of human interaction to acquire a better understanding of information by determining factors such as intent and entities. Instead of simply recognizing words, it must also grasp the message that the user wishes to convey.
NLU is used to improve system understanding of context, however, it has limitations due to natural language’s tremendous complexity. To overcome this, NLU uses parse mechanisms or text processing techniques that turn text into understandable structural data elements, such as tokenization and syntax parsing.
Natural Language Generation (NLG)
The exact opposite of NLU is Natural Language Generation (NLG), which is the process by which machines write like humans. It produces understandable output to enable conversational agents like chatbots and voice assistants.
Aside from interaction, NLG can synthesize written content such as reports, news stories, and product descriptions. NLG converts raw data into human-friendly narratives by performing activities such as creating financial reports and weather forecasts.
Why Does Natural Language Processing (NLP) Matter?
NLP is already widely used, and its popularity is growing as it emerges in a variety of fields. For example, in the retail industry, customer service chatbots use NLP to assist consumers in the healthcare system by analyzing and summarizing the content of the electronic health record.
Most of the existing advanced NLP systems such as GPT-3 & GPT 4.0 can provide elaborative writing on any given topic and will be capable of powering chatbot applications that engage in natural conversation.
Google employs NLP in enhancing the concepts present in a search query, and social platforms such as Facebook employ NLP techniques in identifying hate speech from the many posts made every day.
While NLP technology is gradually enhancing the prospects for increased efficiency, significant development remains to be achieved. There are numerous opportunities for machine learning engineers to apply NLP, which is becoming increasingly important to society. Thus, it looks that now is an excellent moment to conduct this type of research!
Key Components of NLP
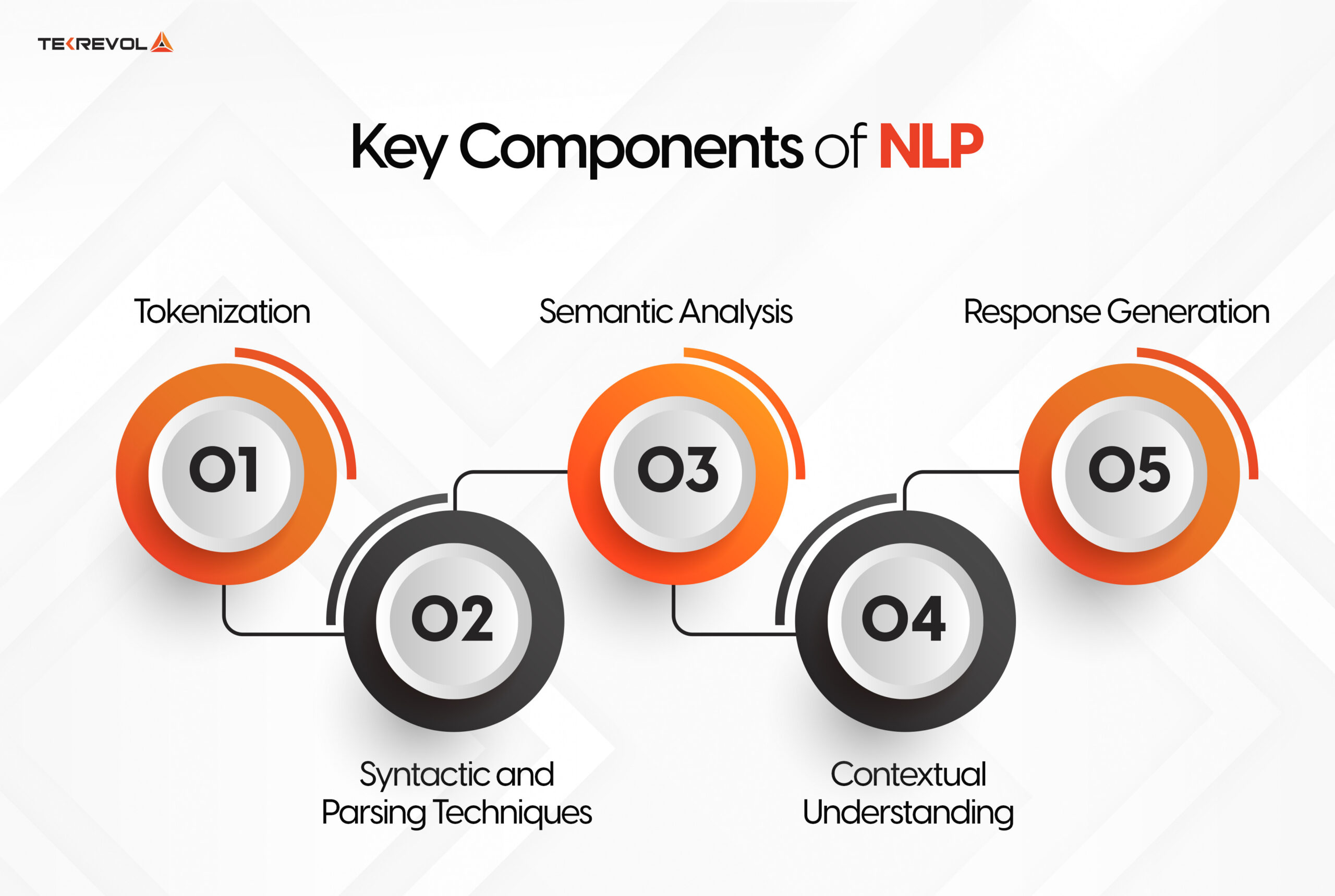
Natural Language Processing (NLP) is the process of analyzing and understanding human communication using complex computer algorithms, and mathematical models. Let’s simplify this process by looking at a few key stages:
Tokenization
To make a text understandable to a machine, it needs to be preprocessed at the outset. This entails deleting non-words such as punctuation and other special characters to create a clean text. Following that, the text is evaluated using a tokenization method, which involves segmenting it into words, phrases, or even sentences.
Syntactic and Parsing Techniques
The correct characterization of sentences is very important for modern NLP. While syntax refers to how words are combined, parsing is the process of understanding the relationship of those structures and forms. This aids machines in determining what portion of the complex sentence is the subject, verb, and object thereby assisting the comprehension of the text.
Semantic Analysis
Semantic analysis examines the meanings conveyed by the words and phrases utilized. It includes assignments such as word sense disambiguation, in which context helps to grasp the meaning of a certain word. This phase is crucial for applications such as translation and sentiment analysis to ensure that the correct message is communicated.
Contextual Understanding
For a machine to comprehend language, it must be able to take context into account. The appropriate interpretation of meaning is consequently concerned with how that meaning fits into the surrounding text as well as the larger discourse. This level of comprehension is attained by powerful natural language processing (NLP) models based on deep learning techniques.
Response Generation
NLP models generate outputs based on their comprehension of the text. Depending on the needs of the process, this could be a translation, a response to a query, or any other appropriate output. The next stage is to review it to ensure that it is as accurate and pertinent as feasible.
How Does Natural Language Processing (NLP) Work?
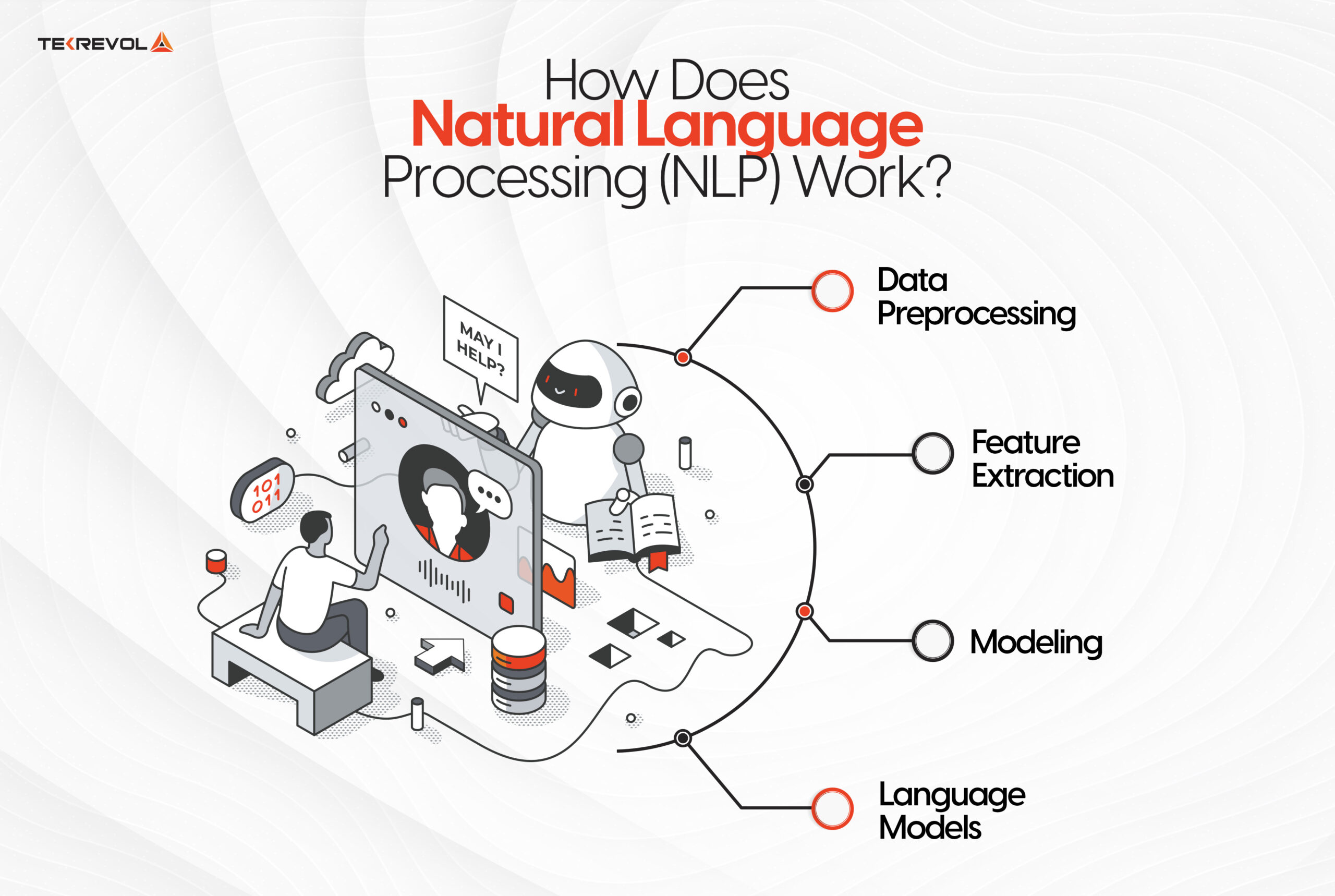
Natural Language Processing (NLP) is the process of allowing computers to interpret and even generate natural language. The essential principle of NLP is the ability to find connections between various components of language such as letters, words, and sentences. Let’s have a look at what NLP models perform using a few procedural steps.
1. Data Preprocessing
However, before reaching the very core of NLP, there is some groundwork needs to be done on the text. This step is beneficial for improving the performance of the model and converting the text to a format that is interpretable by machines. Here are some common techniques used in this stage:
Stemming and Lemmatization: These processes assist in the processes of simplification where words are broken down into the simplest forms. Stemming applies discrete rules (for example, turning “universities, and university” into “universe” whereas lemmatization involves the use of a dictionary for a more accurate approach. Such functionalities are available with tools like spaCy and NLTK.
Sentence Segmentation: This involves breaking down material into more manageable chunks, with each segment representing a significant sentence. What was done here is straightforward in language systems with unambiguous separators, such as English, but it can be difficult in those that don’t, like ancient Chinese.
Stop Word Removal: This technique excludes stop words that contribute less to the interpretation of the text such as ‘the,’ ‘is,’ and ‘an.’
Tokenization: This divides the given text into separate words or phrases, which can be referred to as a tokenized representation of the said text, and can be represented numerically to facilitate the process for a machine. This proves to be helpful as models can exclude irrelevant tokens to enhance efficiency.
2. Feature Extraction
To identify additional numerical characteristics that would describe the documents about the entire corpus, feature extraction is the next step after text pre-processing. Here are some well-liked methods:
Bag-of-Words: This technique counts how many times a word appears in a document. It might, for instance, generate a concept vector according to word frequency and offer a clear foundation for working with the text.
TF-IDF (Term Frequency-Inverse Document Frequency): Using this approach, the overall significance of documents is compared to the relevance of phrases inside them. Two parameters are considered: TF (Term Frequency), which displays the number of times a word appears in a document, and IDF (Inverse Document Frequency), which shows the frequency of that term’s occurrences throughout the complete set of documents. Determining the degree of significance of the words is the last step in the computation.
Word2Vec: Launched in 2013, Word2Vec creates high-dimensional word vectors from text using neural networks. Its two primary modes are the Continuous Bag-of-Words (CBOW) model, which accomplishes the opposite, and the Skip-Gram model, which predicts context words based on the target word. This method works well for obtaining background data.
GLoVE (Global Vectors for Word Representation): Similar to Word2Vec, GLoVE – is used for learning word embeddings but it uses the matrix factorization techniques as the neural networks do while it depends upon simply the co-occurrence counts in the whole of the corpus.
3. Modeling
Once the features are extracted, the data goes through an NLP structure whose purpose is to complete certain tasks. The extracted numerical features can go into various models depending on the goal:
- Classification algorithms include logistic regression, Naïve Bayes, decision trees, and gradient boosting.
- It is also possible to use hidden Markov models and n-grams for named entity recognition.
- Deep neural networks can be trained without using extracted documents by using TF-IDF or Bag-of-Words matrix inputs.
4. Language Models
A language model essentially defines a probability distribution for the next word given a sequence of words as input. For example, probabilistic models’ predictions are based on a phenomenon known as the Markov assumption. Specifically, these models take word embeddings and return a distribution of probabilities for the next word in the given sequence.
For example, BERT, which can recognize language in enormous text corpora(such as Wikipedia), may be taught for specialized tasks such as factual verification and headline-generating.
Different Uses of NLP
Natural Language Processing (NLP) has become an inseparable part of many industries and that is mainly due to their processing capabilities of the text. Here are some of the key ways NLP is being used:
Social Media: It enables the qualitative analysis of the sentiment within the tweets, posts, and comments that organizations have posted, enabling one to track the trend and manage the brand image.
Customer Service: NLP chatbots are employed by businesses to handle and reply to customer queries, offer ‘live’ assistance, and forward demands to other sections proactively without having to involve human operators.
Healthcare: NLP is useful in the generation of fresh insights for diagnoses and treatment of illness by analyzing electronic patient records in the medical field.
Legal: NLP helps legal persons, since it is capable of crawling through vast numbers of legal-related documents, abstracting from them necessary information, for instance, case information, to facilitate legal research and analysis.
News: NLP is employed by journalists and media houses to provide summaries of articles to simplify the arduous task of going through various articles without reading long reports.
Furthermore, natural language processing (NLP) is a crucial technique for conversational AI systems such as virtual personal assistants (Siri, Alexa) and chatbots. NLP makes systems more user-friendly by allowing them to identify between human languages and provide more personalized responses.
Fortunately, people can now see how NLP is affecting practically every aspect of the industry’s work with words and information, from increased customer happiness to improvements in the healthcare system.
A Deep Dive into the Power and Potential of NLP
Have you ever stopped to think about how your voice assistant understands what you are saying, or how search engines seem to finish writing your sentence for you while you are typing it? This natural man-to-machine communication is made possible through Natural Language Processing (NLP), a revolutionary branch of Artificial Intelligence (AI) that enables machines to understand, interpret, and even generate human language.
NLP is no longer a buzz term; it’s the basis of modern-day communication software, search engines, chatbots, and even live translation. It’s not just voice recognition or text anticipation—NLP allows machines to understand context, purpose, emotion, and even vagueness, taking us closer to truly intelligent systems.
In this exhaustive guide, we will demystify the workings of NLP—its essential elements, practices, practical applications, and its challenges in emulating the richness and complexity of human communication. Whether you are an AI enthusiast, a software developer, or a business executive venturing into intelligent automation, this guide is a dive into the realm where linguistics and machine learning intersect.
Top Natural Language Processing (NLP) Techniques

NLP is a concept that refers to methods that make it possible to derive useful information from texts written in natural language. Here are some of the most common NLP techniques that clients frequently utilize, described in detail:
1. Aspect Mining
Aspect mining is the process of identifying specific communication pieces contained within a text. The most common use of this technology is part-of-speech (POS) tagging, which organizes a string of words into related categories such as nouns, verbs, adjectives, and so on. This method of categorization is important for finding the grammatical relationships between sentence parts and then analyzing the text.
2. Categorization (Text Classification)
Text classification, also known as text tagging, is the process of sorting text into predetermined categories based on a set of attributes. It works best when used to group vast amounts of text into relevant categories so that the information can be quickly retrieved and evaluated. For example, news stories can be organized into subjects such as political news, sports news, or information technology news, making data organization easier.
3. Data Enrichment
Data enrichment is the process of increasing the value of existing data by extracting prepared material from plain text. Such a procedure may include aspects such as broadening the user’s query to maximize the possibility of matching the most likely keyword inquiries in Information Retrieval systems.
Data enrichment provides context or related phrases, increasing the likelihood of discovering the intended result and, consequently, the quality of the results.
4. Data Cleansing
Data cleansing in the context of text data is the process of purifying the text by removing any information that may interfere with the analysis. This procedure usually comprises several steps, such as:
Tokenization: It is the pre-processing of text to separate the body of text into its essential pieces, known as tokens.
Stemming: It is the process of lowering words to their stems or basic items, such as turning “running” to “run”.
Punctuation Manipulation: Dealing with punctuation marks to increase the readability of texts. Data cleansing further refines the data source by filtering out the noise and improving the definition of the features of interest.
5. Entity Recognition
Entity recognition, also known as named entity recognition (NER), is the process of recognizing certain entities in text, such as persons, organizations, locations, dates, and others. It is a key technique for interpreting loosely specified data, since it may be applied to customer relationship management, information retrieval systems, or any system that needs to recognize and handle specific entities.
6. Intent Recognition
Intent identification is described as the process of determining the use of words or phrases that indicate a certain user’s intention. This strategy is especially beneficial in conversational AI and chatbots, as knowing the user’s intent can help guide the appropriate reaction or action. This technology, also known as intent detection or intent classification, improves user experiences by introducing interactions that are less working and more suitable.
7. Semantic Analysis
Semantic analysis takes into account pragmatic elements of texts so that they can be interpreted in their right context and connection to other words, particularly when certain words have several meanings. This approach, also known as context analysis, aids NLP systems in understanding what a specific word means in a given situation.
8. Sentiment Analysis
The method of recognizing emotions in the text is known as sentiment analysis or opinion mining. This technique is often used in market research, social media listening, and customer feedback analysis to determine whether a certain text has a positive, negative, or neutral bias. It is critical to recognize that sentiment can aid in the definition of common customer beliefs and behavior.
9. Syntax Analysis
Syntax analysis also referred to as syntactic analysis is a process of analyzing a text based on grammatical analysis. The technique used here comes in handy in distinguishing relations between words and how they place them in statements. With the help of syntax, it is possible to enhance the ability of NLP systems when it comes to recognizing and producing grammatically correct texts.
10. Taxonomy Creation
The process of taxonomy creation also entails the invention of structures that work in a hierarchy to present the phenomenon of relationships in a text. This technique assists in knowledge arrangement and definition of terms for various ideas, which enhances search and retrieval. An optimal and well-developed taxonomy may help to optimize the search and introduce favorable changes in content findings.
11. Text Summarization
The goal of text summarizing is to create a short that contains all of the key information from a bigger body of material. It can be used as either an extractive method, in which significant sentences are directly extracted from the source text, or an abstractive method, in which new meaningful sentences are automatically generated to express the entire context. Thus, a text summary is particularly desirable for speedy information exchange and decision-making procedures.
12. Topic Analysis
Topic analysis means identifying recurring themes or topics in a given piece of text. This process, also known as topic labeling, involves looking for themes that appear throughout the text and can help organize ideas or generate original thought. When it comes to topics, this approach can help businesses better understand the trends and interests of customers.
Main Challenges of Natural Language Processing
Natural language processing (NLP) faces several core challenges that stem from the complexity and diversity of human language:
Ambiguity and Context
It is particularly difficult to comprehend how some of the word meanings and phrases are ambiguous. It is critical to use elements that have multiple meanings; for example, the word “pen” can refer to both a writing instrument and an area where animals are housed.
Similarly, terms like ‘flex’ may have different meanings depending on the generation of employees. In the case of NLP models, this issue is addressed by employing techniques such as part-of-speech tagging for context evaluation.
Understanding Synonyms
NLP models are required to distinguish between similar words and/or phrases as well as learn about minor differences in their meanings. For example, while the words good and fantastic both refer to something positive, the level of positive emotion is different. It thus becomes very important to ensure that the models can capture such distinctions, especially from a sentiment analysis perspective.
Sarcasm and Irony
Sarcasm and irony are two of the most difficult issues for algorithms to understand when it comes to natural language. Various research has been done to address this, including a mixed neural network technique, however, the problem persists because figurative languages are heavily context sensitive.
Language Variations and Dialects
An NLP system must be compatible with hundreds of languages and dialects, including regionalisms and slang. This issue becomes much more obvious when discussing a single language like English, where regional dialects such as British English and American English vary. We also note that there exist industry-specific vocabularies, necessitating the development of applicable NLP models.
Training Data
Another problem arises when a huge number of data must be annotated, such as annotating figments of creativity or rarely used phrases. A lack of training data for these elements may lead to bad models.
- Want to overcome the challenges of natural language processing?
- Let TekRevol be your trusted partner in building smart, efficient solutions!
The Future of Natural Language Processing
Natural language processing, or NLP, presents a plethora of exciting opportunities that have the potential to drastically alter how humans interact with technology and understand language. Here’s a look at key trends shaping the future of NLP:
Transfer Learning: Transfer learning is revolutionizing NLP by enabling models to leverage previously acquired knowledge from one task for other tasks and as a result improving the rate at which these models can be retrained for new tasks.
Multimodal NLP: As NLP incorporates image and voice data, it will indeed open up the scenario of full-fledged systems that can process text, image, and voice simultaneously and therefore, provide contextually smarter applications.
Real-Time Language Processing: The next generation of NLP technology will include time-sensitive features to enable faster and more responsive interactions in service platforms such as voice-activated assistants, instant messaging bots, and live event interpreters.
Ethical and Responsible AI: As the ethical issues related to NLP models continue to gain importance in the future, these systems will be built and designed densely in terms of fairness, transparency, and accountability.
This is an ideal time for enterprises to take a significant step forward in their growth and development. To achieve this successfully, you’ll need the correct AI development services to help you optimize innovative technologies.
The Bottom Line
Natural language processing (NLP) is transforming corporate and human interactions with technology. It improves the naturalness and intelligence of all human-language exchanges, from virtual personal assistants to developed customer service.
As more businesses integrate NLP into their systems and processes, they benefit from increased productivity, better business decisions, and customer satisfaction. Therefore, in an increasingly digital environment, technology has the potential to enhance not only operations but also how organizations function.
As we can see, the world of NLP is evolving, and now is the ideal time for all businesses to implement these technologies and stay ahead of their competitors in the market. NLP is the future of business, and it will assist market pioneers achieve success.









